蜜蜂采集器的使用教程 - 采集北京新发地市场农产品价格行情
本文以北京新发地市场农产品价格行情采集为例,介绍列表页网址中的时间格式化参数的使用方法。
页面分析
数据来源:北京新发地市场官网。
使用浏览器打开北京新发地市场官网,按F12打开浏览器的开发者工具。设置时间范围为当天,点击“查询”。可以看到.../getPriceData.html这样的POST请求,返回内容为JSON格式。我们试着将POST请求的网址和参数改装成GET方式,发现也可以正常访问,因此,就以此地址的GET请求来采集。
采集规则实现
格式化网址源:.../getPriceData.html?limit=1000¤t=1&pubDateStartTime=[参数]&pubDateEndTime=[参数]&prodPcatid=&prodCatid=&prodName=,两个参数都是时间变化格式,且时间格式为yyyy-MM-dd,从0到0天,也就是只采集当天数据。这里将limit改为1000,因为一天的数据是469条,我们一次获取完毕,避免频繁请求。勾选“列表页网址即为内容页网址”。

内容采集。各标签均勾选“页内循环采集标签内容”,提取方法为JsonPath。在“循环采集”设置页面,勾选“每个循环采集的结果以新记录保存”。这里,因为是Json方式获取的,所以采用循环采集的方式,将每个子项都采集为一个新纪录。
id:JsonPath提取规则为["list"][*]["id"];一级分类:JsonPath提取规则为["list"][*]["prodCat"];一级分类id:JsonPath提取规则为["list"][*]["prodCatid"];添加标签数据二次处理项“字符串替换”,将null替换为空,因为这里会出现null值;二级分类:JsonPath提取规则为["list"][*]["prodPcat"];二级分类id:JsonPath提取规则为["list"][*]["prodPcatid"];添加标签数据二次处理项“字符串替换”,将null替换为空,因为这里会出现null值;品名:JsonPath提取规则为["list"][*]["prodName"];最低价:JsonPath提取规则为["list"][*]["lowPrice"];平均价:JsonPath提取规则为["list"][*]["avgPrice"];最高价:JsonPath提取规则为["list"][*]["highPrice"];规格:JsonPath提取规则为["list"][*]["specInfo"];产地:JsonPath提取规则为["list"][*]["place"];单位:JsonPath提取规则为["list"][*]["unitInfo"];发布日期:JsonPath提取规则为["list"][*]["pubDate"]。

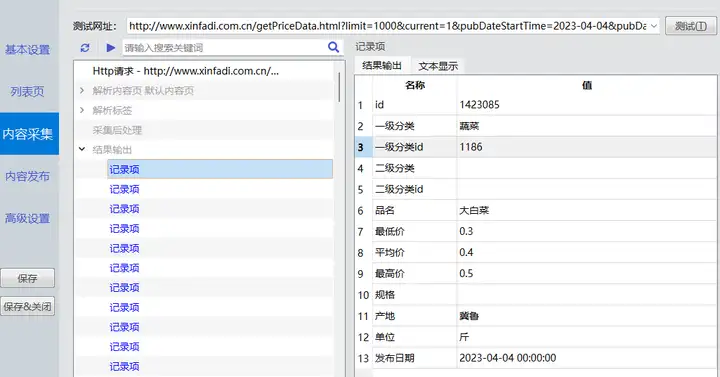
运行采集任务,查看采集数据结果。
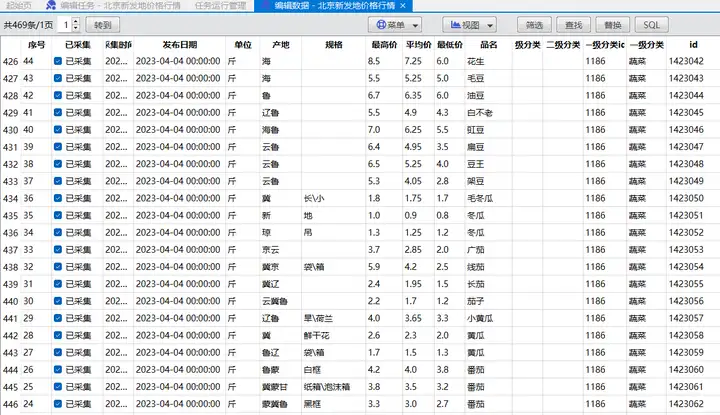
至此,就实现了北京新发地市场农产品价格行情数据的采集。
![[视频] 如何将蜜蜂采集器的采集数据发布为xlsx格式的Excel表格文件](https://picx.zhimg.com/v2-a050c70664e1a1452edef15ceae80740_r.jpg)
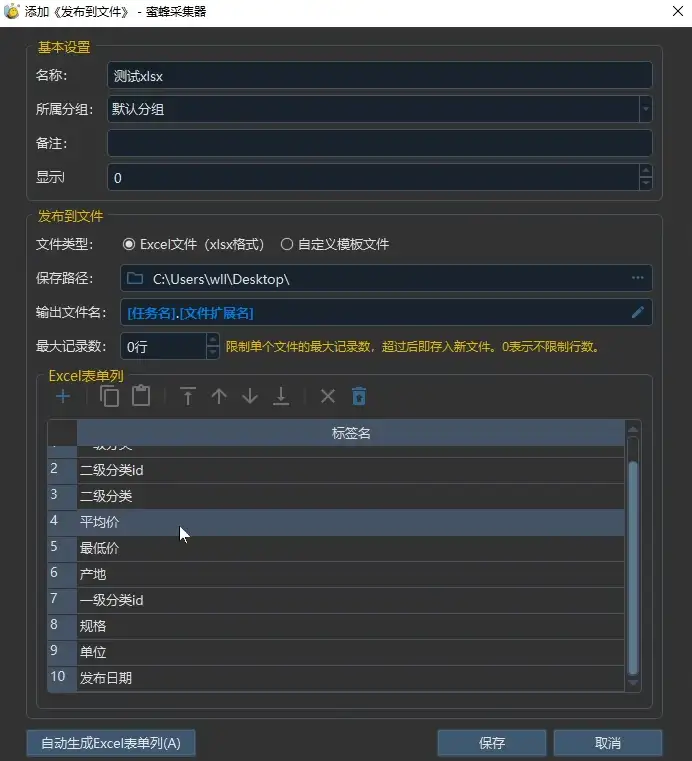
![[视频] 使用蜜蜂采集器实现“采集一次再发布到多个站点”的几种方法](https://pic4.zhimg.com/80/v2-c5ea1faf6347751401e773fded612a2f_720w.webp)
发表评论 取消回复