蜜蜂采集器的使用教程 - 经济数据采集之海关进口重点商品数据采集处理
本文以海关进口重点商品数据采集为例,演示如何将表单数据保存为Excel文件。
页面分析
数据来源:中国-中东欧国家海关信息中心。
使用浏览器打开"监测预警 - 数据经纬",找到标题包含"全国进口重点商品量值表(人民币值)"的主题。这里数据很多,不同的文章格式不太一样,有的是文本页面,有的则是Excel文件地址,因此,我们只关注"全国进口重点商品量值表(人民币值)"系列的文章,以便统一采集的处理方式。采集完毕后,将文章内的表单存储到文件中,且要求文件能使用Excel打开查看。
按F12打开浏览器的开发者工具。刷新页面,“开发者工具”的“网络”请求列表中可以看到.../MONITORING/DATA_COLUMN_LIST_RIGHT_CN_4.html这样的请求,即为文章列表。这里,网页地址请求的内容并不包含文章列表的。加载完成后的网页内容中,有个iframe子页面,文章列表在iframe子页面中。因此,我们查找其他网络请求,即可找到.../MONITORING/DATA_COLUMN_LIST_RIGHT_CN_4.html这样的地址,其中的4是翻页的页码。
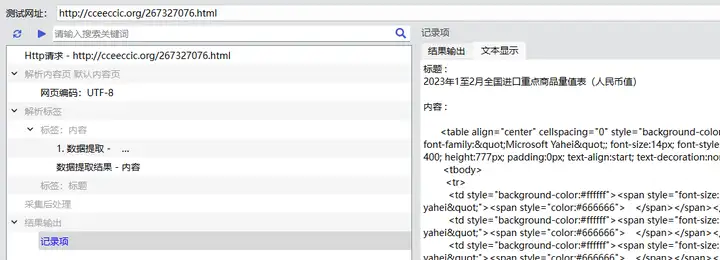
打开"2023年1至2月全国进口重点商品量值表(人民币值)"这样的文章地址,同样使用浏览器“开发者工具”分析。页面内容比较简单,具体的表单内容在table标签内。为了方便采集处理,我们直接将网页的table标签内的内容保存到文件中。然后,使用Excel打开这个HTML格式的文件,即可显示表单。这种处理方法简单直接,将表单解析处理交给Excel软件。如果需要直接解析表单,可以借助插件等方式实现。
采集规则实现
格式化网址源:.../MONITORING/DATA_COLUMN_LIST_RIGHT_CN_[参数].html,参数为数字变化格式。
网址采集。网址标签的区域起始为</iframe>,区域结束为<div class="m-style M-box">,匹配单元起始为<div class="tz_list">,匹配单元结束为<div class="data">,解析方式为自动解析网址,标签数据二次处理中添加前后缀,前缀添加/。标题标签的解析方式为字符串截取,起始字符串为<p class="title">[*]>,结束字符串为</a>,内容过滤条件为必须包含全国进口重点商品量值表(人民币值)。
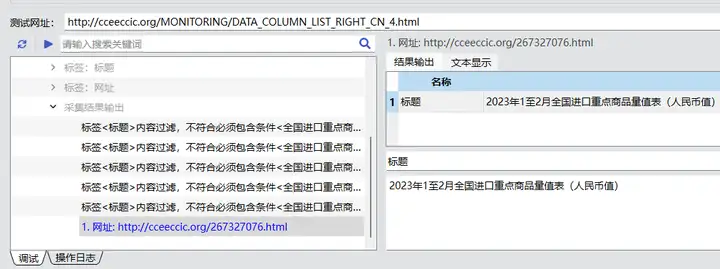
内容采集。内容标签采用通配方式匹配来提取,提取规则为<div class="article_c" id="divColumnsContent">[参数]</table>,输出格式为[参数1]</table>。
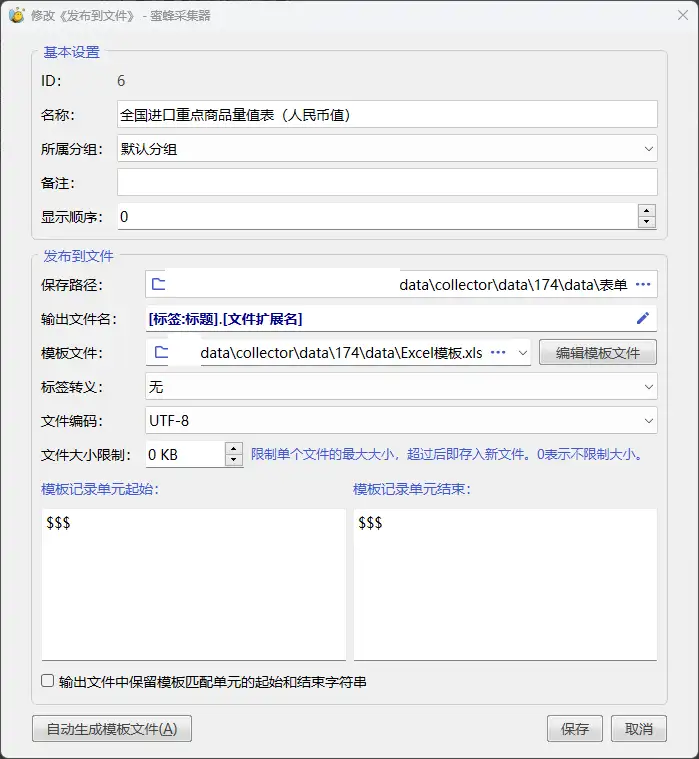
内容发布。“发布到文件”管理器中,添加一个文件发布配置,其中的“输出文件名”为[标签:标题].[文件扩展名],模板文件路径自定义并且后缀为.xls,标签转义设置为无。后缀为.xls,方便后面直接使用Excel打开文件。模板内容本身是一个HTML格式,模板文件内容如下:
$$$<html><head><title>[标签:标题]</title></head><body>
[标签:内容]
</body></html>$$$内容发布通道中添加一个“发布到文件”通道,并选中刚刚添加的文件发布配置。
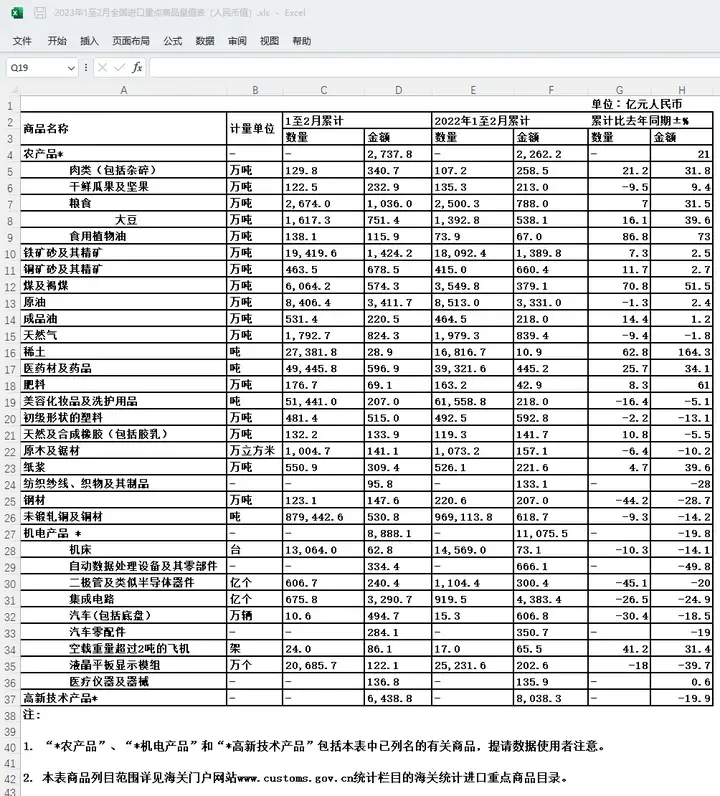
至此,就实现了海关进口重点商品数据的采集。
![[视频] 如何将蜜蜂采集器的采集数据发布为xlsx格式的Excel表格文件](https://picx.zhimg.com/v2-a050c70664e1a1452edef15ceae80740_r.jpg)
![[视频] 使用蜜蜂采集器实现“采集一次再发布到多个站点”的几种方法](https://pic4.zhimg.com/80/v2-c5ea1faf6347751401e773fded612a2f_720w.webp)
发表评论 取消回复