现在很多网站采用异步请求方式来展现网页内容,而异步请求中的内容多为JSON格式。如果采用可视化采集技术,则要展示这样的页面内容,需要先加载各种css、js文件,速度较慢,网页的可视化展示也比较占用系统资源;采集网页过程中页面呈现可能偶尔会卡住,也非常影响体验。
对这种JSON格式异步数据的采集,如果采用传统采集方式,使用JSON表达式解析,也可以很方便。
下面以同花顺的“7×24小时要闻直播”为例,使用蜜蜂采集器进行简单的采集测试。
我们先使用浏览器访问同花顺的“7×24小时要闻直播”页面https://news.10jqka.com.cn/realtimenews.html,按F12打开浏览器的开发者工具。查看“网络”面板的访问列表,逐个查看,进而找到新闻列表的请求地址: https://news.10jqka.com.cn/tapp/news/push/stock/?page=1&tag=&track=website&pagesize=400 ;点击“刷新”按钮,得到新闻列表的请求地址: https://news.10jqka.com.cn/tapp/news/push/stock/?page=1&tag=&track=website&ctime=1678964322 。刷新参数ctime应该是上一次刷新获得的记录中最近一条新闻的创建时间,刷新请求应该是获取该时间到当前时间之间的所有新闻,还可以进一步分析出此时pagesize的值为默认值20。
这里,对采集而言,ctime的意义不大,因此,我们直接采集https://news.10jqka.com.cn/tapp/news/push/stock/?page=1&tag=&track=website&pagesize=400地址,即可。其页面的内容如下:
{"code":"200","msg":"成功","time":"1678970428","data":{"list":[{"id":"1577497","seq":"645580185","title":"***","url":"https://news.10jqka.com.cn/20230316/c645580185.shtml","appUrl":"https://news.10jqka.com.cn/m645580185/","shareUrl":"https://news.10jqka.com.cn/tapp/news/share/645580185/","color":"1","tag":"公告,A股","tags":[{"id":"34843","name":"公告"},{"id":"21103","name":"A股"}],"ctime":"1678970281","rtime":"1678970281","source":"","nature":"0","stock":[{"name":"赛微电子","stockCode":"300456","stockMarket":"33"}],"field":[],"short":"***","import":"0","tagInfo":[{"id":"50044798","name":"瑞典","score":"0.804","type":"1"},这是一个标准的JSON格式内容。使用采集器内置的JSON分析工具查看,即可获得需要的JSON表达式路径。此处略过。
现在我们新建一个采集规则,“列表页”中添加一条普通网址项,内容为https://news.10jqka.com.cn/tapp/news/push/stock/?page=1&tag=&track=website&pagesize=400。“网址采集”中,添加标签网址,解析方式为JsonPath,提取规则为["data"]["list"][*]["appUrl"],这里使用*表示选择对象或数组中的所有元素;添加标签ID,解析方式为JsonPath,提取规则为["data"]["list"][*]["id"];添加标签标题,解析方式为JsonPath,提取规则为["data"]["list"][*]["title"];添加标签摘要,解析方式为JsonPath,提取规则为["data"]["list"][*]["digest"];添加标签时间,解析方式为JsonPath,提取规则为["data"]["list"][*]["ctime"]。如下图:
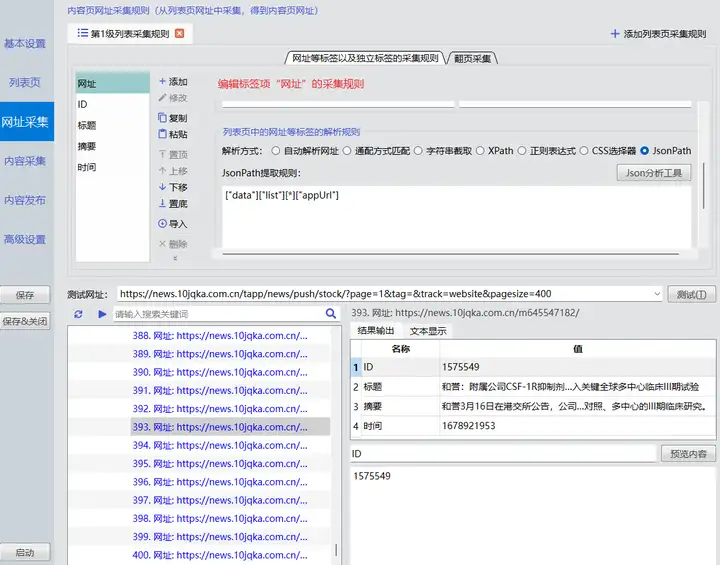
至此,我们就实现了从JSON文本中采集数据的功能。
希望这篇文档的介绍,可以抛砖引玉,也能让你了解采集器的使用,可以去蜜蜂采集器官网https://zhi200.com下载最新版本客户端。


发表评论 取消回复